Alteryx Write Data In-DB Toolを用いた新規テーブル作成①(Redshift環境構築~Alteryxからの接続)
AlteryxのIn-DB機能にて使用可能なWrite Data In-DB Tool(データ書き込みIn-DBツール)を用いて,データベース上にテーブルを作成する機会がありました.ツールの使用に際して,いくつか確認・調査の必要があり,検証用の環境を用意する必要があったので,一連の流れを記事として残しておくこととしました.本記事では,Redshiftのクラスター構築からAlteryx経由での接続・データ表示までの手順を記載しています.実際にWrite Data In-DB Toolを使用する工程は,次の記事に記載する予定です.
本記事の内容は下記の通りです.
1. Alteryx
1.1. 概要
本題に入る前に,Alteryx(アルタリクス)について簡単に説明を.
Alteryxを一言でいうなれば,GUI版のSQLというとイメージしやすいでしょうか.データの準備,クレンジングから一部分析までもをワンストップで実施可能なツールです.SQLはデータベース上のデータを操作する言語ですが,Alteryxはデータベースのみならず,現場でよく用いられるようなExcelやCSVファイルといった様々なインプットデータに対応し,その加工を柔軟かつ強力にサポートします.
実際にAlteryxでデータを操作する際は,「ワークフロー」というものを作成します.ワークフロー内に,特定の機能を持つアイコンを配置し,データの加工を行っていきます.SQLやその他プログラミング言語では,実際に「コード」にあたる箇所を,このワークフローが代替しており,各種アイコンの意味がわかれば,プログラミング言語に習熟することなくその成果物や処理を再現可能なまま共有することが可能となります.
1.2. In-DB機能
alteryxには,実行環境のメモリ上ではなく,直接データベース上で処理を実行可能な機能が備わっています.これをIn-DBといい,通常よりも使用可能な処理(ツール)は限定されますが,充分に強力なデータ加工をGUIで実行可能です.今回,仕様の調査対象となる,「Write Data In-DB Tool」はその名の通りIn-DB機能となります.
alteryxのIn-DB機能では,本記事で扱うAmazon Redshiftをはじめとした主要なデータベース/データウェアハウスと連携することが可能です.詳細は公式のドキュメントをご参照ください.
Tableau等のBIツールでデータの可視化をする際は,元データをある程度可視化しやすい形まで整形する必要がある場合が多々あるかと思います.BIツール側でもデータの加工自体は可能ですが,元データからの加工処理が複雑な場合には,alteryxのようにデータ加工に特化したツールを用いる場合もあるでしょう.
他のBIツールもデータベースと連携可能な場合が多いので,In-DB機能を通すことでほぼノンコーディングでデータ加工~可視化までを容易に実施可能となります.
1.3. Write Data In-DB Tool
In-DB機能で使用可能なツールの一つに,データベースに直接テーブルを作成可能なWrite Data In-DB Toolがあります.
このツールを使用することで,Alteryxで加工済みのデータを新規テーブルとしてデータベース上に作成・更新といった処理を実行可能となります.ツールの詳細は下記の公式ドキュメントをご参照ください.
2. データ連携の流れ
今回は,Amazon RedshiftをIn-DB機能で接続する対象とし,Write Data In-DB Toolの仕様を確認します.Redshiftとの連携イメージは下図の通りです.
※本記事では,Alteryxのツール仕様の確認が主目的のため,Redshift側の構成はほぼデフォルト(最低限)です.
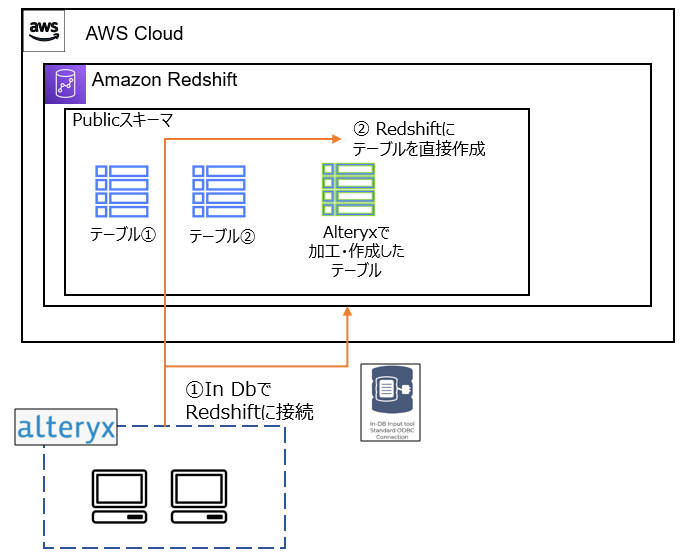
3. Redshift環境の構築
3.1. クラスターの作成
Amazon Redshiftは,Amazon Web Services(AWS)が提供する,データウェアハウス(DWH)です。Redshiftは「PostgreSQL」がベースとなって開発されており,クラスターと呼ばれる単位での構成となっています.作成手順は下記通りです.
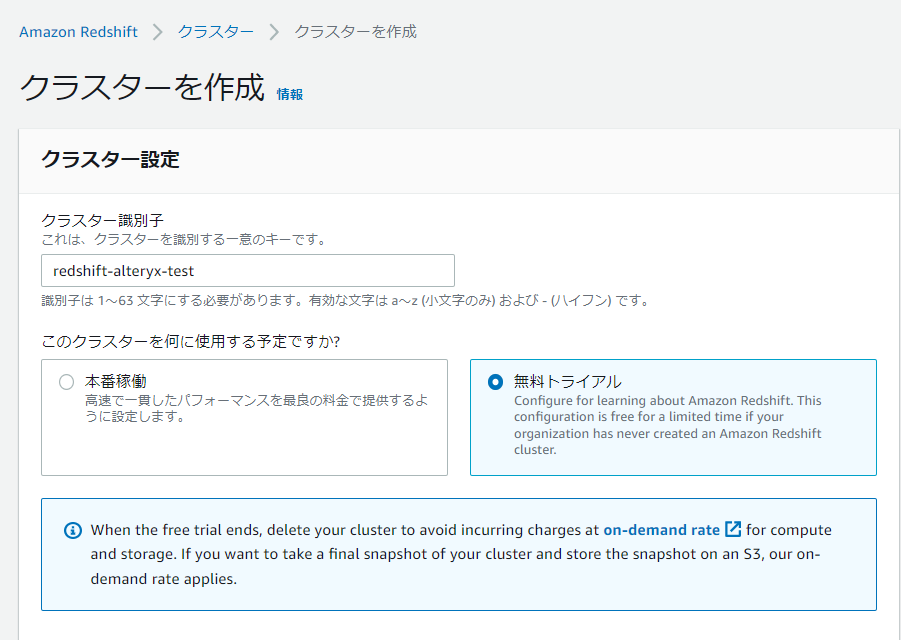
①AWSマネジメントコンソールよりRedshiftを検索し,「クラスターを作成」を押下します.

②クラスターの名称,用途を選択します.今回は検証用のため「無料トライアル」を選択します.
③管理者名,管理者パスワードを設定します.

最後に「クラスターを作成」を押下すると,設定した内容でクラスターが作成されます.
デフォルトの設定では,クラスター作成とあわせて「dev」という名前のデータベースが作成され,サンプルデータがインポートされます.今回はそのデータを使用していくこととします.
3.2. 外部接続の許可
クラスターが作成できたら,クラスターの選択画面より対象のクラスターを選択します.

作成されたクラスターについて,デフォルトでは,パブリックアクセスが「無効」となっているのでこの設定を「有効」とし,Alteryxから接続可能なように変更します.

パブリックアクセスが有効化されると,プロパティタブの「ネットワークとセキュリティの設定」欄の「パブリックアクセス可能」が「有効」となります.

4. Alteryxの準備
手元の端末にAlteryxを実行可能な環境を用意します.ツールを使用するには,ライセンスの購入が必要ですが,Alteryxを使用したことのない人や学生等は,下記の公式サイトより無料トライアルを活用できます.なお,無料トライアルの期間が終了すると,ライセンスの認証が切れ,Alteryxを使用することはできなくなりますが,自動的に料金が発生するようなことはありません.
インストールとライセンスの認証が完了すると,実際にツールを使用可能となります.今回調査対象となるIn-DBに関するツールは,画面上部の「ツールパレット」にて「インデータベース」タブを選択することで一覧が表示されます.

5. Redshiftへの接続
5.1. 接続方法
新規のワークフローを開き,「データ入力ツール」をドラッグアンドドロップします.

ツールの設定より,データ接続方法として「データソース」を選択します.すると下記のように使用可能なデータソースが一覧化されるので,「Amazon Redshift」のODBC接続を選択します.

下記のようなポップアップが表示されたら,「ODBCアドミニストレーター」を押下します.

「ドライバー」タブを開き,Redshiftのドライバーがインストールされていることを確認します.

Redshiftのドライバーのインストールを確認出来たら,「ユーザーDNS」タブを開き,「追加」を押下し,「Amazon Redshift」ドライバーが選択された状態で「完了」を押下します.

下記のような設定を入力する画面が表示されたら,接続対象となるデータベースの名称・接続するユーザーの情報を入力します.これらの情報はRedshiftのクラスター情報画面から確認できます.

必要な情報を入力し,画面下「Test」を押下し下記のポップアップが表示されれば,問題無いです.

5.2. In-DB接続の管理
続いてIn-DB接続の管理を行います.「接続In-DBツール」をドラッグアンドドロップし,「接続名を作成または選択」から,「接続を管理」を押下します.

「接続の管理」にて,今回は下記の通り接続するユーザーごとの接続を作成します.ひとまず,管理者ユーザーである「awsuser」に関する接続を作成します.

その後,先程作成した接続方法(今回の接続名は「awsuser」)を選択すると,下記の通り,テーブルの選択画面が表示されます.

試しに「public」スキーマの「category」テーブルを選択し下記の通りフローを実行すると,データの内容を一部確認することができます.

6. まとめ
今回は,Redshiftのクラスター構築からAlteryx経由での接続・データ表示までを実施しました.これにより,以降はデータ分析に必要な前処理工程を,Alteryxの強力なデータ加工機能を用いてノンコーディング実施できます.
次の記事では,データ分析に用いるためにAlteryxで加工したデータを新規テーブルとして実際にRedshift上に作成する手順をしながら表記のWrite Data In-DBツールの詳細を確認します.