HugoとNetlifyでブログの環境構築 | 設定まとめ
前回の記事で,HugoとNetlifyによるブログ環境を構築してみました.Hugoでは,様々なブログのテーマを利用でき,Tranquilpeakを使用しました.ブログの細々した設定にあたり,色々と調べる必要があったので,参考とした記事とあわせてまとめてた記事になります.
※随時更新します.
設定関連
文字フォント・サイズの変更
下記の2つの手順で変更可能です.
1.所定のディレクトリに参照するCSSファイル作成
デフォルトの文字フォントやサイズ,色等を変更する場合は,custom cssを追加します.
前回の記事の状態だと,ブログのディレクトリ構成は下記のようになっています.
. ├── archetypes ├── config.toml ├── content ├── data ├── layouts ├── netlify.toml ├── public ├── resources ├── static └── themes
staticディレクトリ配下に,cssディレクトリを作成し,そこにmystyle.cssを追加します.(ファイル名は任意)
mkdir static/css touch mystyle.css
下記のような感じで,細かな設定をこのCSSファイルに記載していけばよいです.
下記の例では,本文のフォントをメイリオにし,サイズも少し大きくしています.このあたりはHTML,CSSの知識がいるのでより細かく設定をする場合はそちらの勉強も必要ですね...
p { font-family: 'メイリオ', 'Meiryo','MS ゴシック','Hiragino Kaku Gothic ProN','ヒラギノ角ゴ ProN W3',sans-serif; font-size: 16px; }
2.config.tomlを編集
ファイルを追加しただけでは反映されないので,config.tomlに下記を追記します.
# Custom CSS. Put here your custom CSS files. They are loaded after the theme CSS; # they have to be referred from static root. Example [[params.customCSS]] href = "css/mystyle.css"
詳細はユーザーマニュアルが参考になります.
背景画像の変更
背景画像は,下図の赤枠で囲った部分になります.フォントと同様の手順で設定可能です.

1.画像ファイルを配置するディレクトリを作成
ブログのルートにあるstaticディレクトリ配下に,imagesディレクトリを作成し,そこに表示させたい画像ファイルを追加します.(ここでは,marine.jpgというファイルを追加.)
mkdir static/images
2.config.tomlを編集
config.tomlの[params]欄にルートからのパスを追記します.
[params] # Your blog cover picture. I STRONGLY recommend you to use a CDN to speed up loading of pages. # There is many free CDN like Cloudinary or you can also use indirectly # by using services like Google Photos. # Current image is on AWS S3 and delivered by AWS CloudFront. # Otherwise put your image, for example `cover.jpg` in folder `static/images/`, # and use relative url : `images/cover.jpg` coverImage = "images/marine.jpg"
こちらは,テーマのサンプルサイトのconfig.tomlが参考になります.
※ドキュメントでは,高速化のためにCDN(Content Delivery Network)の利用が推奨されています.
記事作成
記事一覧に概要のみ表示する
Hugoでブログを作成すると,ホーム画面で記事の一覧が表示されます.一覧では,記事のタイトルと本文が表示されるのですが,特に設定しないと長い本文が表示されてしまいます.

マークダウンにて,<!--more-->を追加することで,その前後の内容を記事一覧に表示させる/させないの制御が可能です.
--- title: "My First Post" date: 2022-09-17T11:43:55+09:00 draft: false --- 記事の概要として,記事一覧画面に表示される. <!--more--> 以降は,記事一覧画面には表示されない. # header1 本文
記事に画像を表示する
画像ファイルの配置場所
Hugoで画像ファイルを管理する際は,ルート配下のstaticを使用する方法と,
ページバンドルという方法で,記事(マークダウンファイル)と一緒に管理する方法があります.現時点ではstaticを使用する方法を記載します.ページバンドルを使用する方法も,今後追記したいと思います.
なお, こちらの記事|天才まくまくノートで画像ファイルの管理について詳しくまとめてくださっています.
static ディレクトリを使用する場合
背景画像と同じディレクトリを使用します.
下記では,images配下にさらにsubディレクトリを作成し,記事に追加したい画像としてbase-octocat.svgを格納しています.
static
├── css
│ └── mystyle.css
└── images
├── marine.jpg →背景画像
└── subdir
└── base-octocat.svg →記事に追加したい画像
mdファイルの記述方法
所定のディレクトリに画像を配置したら,そのファイルを指定するようにマークダウンに記述すればよいです.マークダウンへの記述方法として下記の2種類をまとめておきます.
Markdown formatting
一般的にマークダウンで画像を追加する方法です.下記のように記述します.

Shortcodes
Markdown formattingではできないサイズの変更などに対応した方法です.パラメータを指定することで,細かな制御が可能で,下記のように記述します.
{{< figure src="/images/sub/base-octocat.svg" class="center" width="320" height="320" >}}
詳細や設定可能な項目は,下記から確認できます.
マークダウンに次のように記述し
---
title: "Image Test"
date: 2022-09-24T15:36:11+09:00
draft: true
---
**markdown formatting**

**Shortcodes**
{{< figure src="/images/sub/base-octocat.svg" class="center" width="320" height="320" >}}
ローカルで確認すると下図のようになります.

サイズ等を柔軟に変更できるShortcodesによる方法が良いかもしれません.
外部連携
Netlify, GitHubとの連携
Hugoは,サイトのホスティングサービスとしてNetlifyを使用できます.また,NetlifyをGitと連携することでソースがGitHubにプッシュされると,Netlify側にインストールされたHugoで,サイトが自動的にデプロイされます.
publicディレクトリをGitHubにプッシュしない
Hugo自体は静的サイトジェネレーターとして,マークダウンで記事を作成後,hugoコマンドの実行によりpublicディレクトリ配下に静的サイトのソースを生成します(HTMLファイル等が作成される).Netlifyを使用する場合,この部分をNetlify側で対応してくれるので,GitHubにプッシュする必要はありません.なので,publicディレクトリ配下はGitHubにプッシュされないように.ルートにて.gitignoreを下記の通り作成しておくとよいです.
touch .gitignore echo public/ >> .gitignore
参考サイト
BALLOON | FU-SEN blog | Tranquilpeakのテーマを使用して作成したブログ一覧にも取り上げられているブログです.
つちのこブログ | Tanquilpeakの設定を詳しくまとめてくださっています.
How I Build This Site | Traquilpeakでのブログ構築手順をはじめからてくださっています.
画像ファイルを Markdown ファイルと同じディレクトリに置く (Page Bundle) - まくまくHugoノート | 画像ファイルの管理方法について詳しくまとめられている記事です.
HugoとNetlifyでブログの環境構築
いまのところ,はてなブログにてブログを作成していますが,静的サイトジェネレーターであるHugoというサービスを使えば,下記のような利点があることから,将来の移行を見据えつつ,環境構築をした際のメモになります.ホスティングサービスには,Netlifyを使用しました.
よさそうな点
・提供される様々なテーマから好みのものを選択可能
・markdownで記事を作成可能
・ソースはGitHubで管理可能
・変更内容をプッシュすれば,自動でサイトも更新される
作成したブログはこちらです.
前提条件
下記の環境で実施しています.
Ubuntu 20.04 on Windows hugo_extended_0.101.0_Linux-64bit
Hugoのインストール
下記の通りインストールし,解凍します.
wget https://github.com/gohugoio/hugo/releases/download/v0.101.0/hugo_extended_0.101.0_Linux-64bit.tar.gz tar -zxvf hugo_extended_0.101.0_Linux-64bit.tar.gz
PATHを通し,確認します.
hugo version
hugo v0.101.0-466fa43c16709b4483689930a4f9ac8add5c9f66+extended linux/amd64 BuildDate=2022-06-16T07:09:16Z VendorInfo=gohugoio
マニュアルに従って,簡単なサイトを作ってみます.
#新規サイトを作成
hugo new site quickstart
tree
上記のコマンドを実行すると,quickstartというディレクトリが作成されます.はじめは下記のような構成となっていました.
. ├── archetypes │ └── default.md ├── config.toml ├── content ├── data ├── layouts ├── public ├── static └── themes
cd quickstart
git init
テーマのインストール
サイトのテーマをインストールします.
ここでは,「tranquilpeak」というテーマを使用しています.
git submodule add https://github.com/kakawait/hugo-tranquilpeak-theme.git themes/tranquilpeak
「tranquilpeak」テーマのディレクトリ配下は,下記のような構成となっていました.
cd themes/tranquilpeak tree -L 1
. ├── CHANGELOG.md ├── Gruntfile.js ├── LICENSE ├── README.md ├── archetypes ├── docs ├── exampleSite ├── i18n ├── images ├── layouts ├── package-lock.json ├── package.json ├── release.sh ├── showcase.png ├── src ├── static ├── tasks └── theme.toml
下記のように,他にも多くのテーマが存在するので,好みのものを選択できます.
サイトのルートディレクトリに移動します.
サイトのデザインを変更するには,主にconfig.tomlに変更を加えていくことになるかと思います.
まずは,使用するテーマに関する記述を加えます.
cd ../.. echo theme = \"tranquilpeak\" >> config.toml
これで,使用テーマの最低限の設定ができたことになります.
記事の作成
次に,下記のコマンドでサンプル記事を作成します.
hugo new posts/my-first-post.md
contentsディレクトリ配下にmy-first-post.mdが作成されます.
雛形の内容は下記の通りです.
--- title: "My First Post" date: 2022-07-29T23:01:51+09:00 draft: true ---
このマークダウンファイルに記事の内容を書くだけでよいのはすごく便利です.drafttrueとなっているのは,このままでは本番環境で公開されないことを意味します.
下記のコマンドを実行すると,ローカルホスト上で,サイトを確認することができます.-Dオプションは--buildDraftsの略で,draft=trueの記事も確認することができます.
hugo server -D

記事を追加します.基本的には同様のコマンドで雛形を作成し,内容を記載していくのみです.
hugo new posts/my-second-post.md
--- title: "My Second Post" date: 2022-07-29T23:11:40+09:00 draft: true --- # Contents Hello hugo

ローカルでサイトをチェックし、問題がなければ,draftをfalseに変更します.hugoコマンドを実行するとpublicフォルダ配下に,静的なHTMLファイルが出力されます.
Github側の準備
GitHubで,ブログ用のリモートリポジトリを作成しておきます.これまでに作成したサイトディレクトリから,GitHub上に作成したリモートリポジトリにソースをプッシュします.
git add . git commit -m "first commit" git branch -M main git remote add origin https://github.com/y-yasutomo/XXXXXXX.git git push -u origin main
Netlify側の準備
Netlifyでは,アカウント登録・Gitと連携後,Import an existing project from a Git repositoryより,対象のリポジトリを選択するのみで,サイトURLが表示され,そこから内容を確認することができます.

ソースプッシュによる自動更新
作業ディレクトリにて,下記のコマンドを実行し新しい投稿を作成してみます.
hugo new posts/my-third-post.md
draftをfalseに変更し,変更内容をリモートリポジトリにpushすると,NetlifyのURLで表示されるサイトでも,変更内容が反映されます.自動更新がうまくいかなかった場合でも,Netlify上でデプロイログを確認できるので,ここから原因を調査することが可能です.

カスタマイズ
サイトを少しカスタマイズしてみます.
config.tomlを下記のように編集しました.ドキュメントをみながら手元で変更内容を確認しながら編集した形になるので,また別記事でこの内容はまとめたいと思います.
baseURL = '/' title = 'My New Hugo Site' languageCode = 'ja' defaultContentLanguage = "ja" theme = 'tranquilpeak' [author] name = "ystomo" job = "SE" location = "Japan" # Your Gravatar email. Overwrite `author.picture` everywhere in the blog gravatarEmail = "XXXXX@XXXXX" [params] sidebarBehavior = 2 # post閲覧時にサイドバーをひっこめるオプション clearReading = true thumbnailImage = true dateFormat = "2006-01-02" thumbnailImagePosition = "left" autoThumbnailImage = true coverImage = "images/cover-marine.jpg" imageGallery = true hierarchicalCategories = true syntaxHighlighter = 'highlight.js' # Your Gravatar email. Overwrite `author.picture` everywhere in the blog gravatarEmail = "XXXXX@XXXXX" [[menu.main]] weight = 1 identifier = "home" name = "Home" pre = "<i class=\"sidebar-button-icon fas fa-lg fa-home\" aria-hidden=\"true\"></i>" url = "/" [[menu.main]] weight = 2 identifier = "categories" name = "Categories" pre = "<i class=\"sidebar-button-icon fas fa-lg fa-bookmark\" aria-hidden=\"true\"></i>" url = "/categories" [[menu.main]] weight = 3 identifier = "tags" name = "Tags" pre = "<i class=\"sidebar-button-icon fas fa-lg fa-tags\" aria-hidden=\"true\"></i>" url = "/tags" [[menu.main]] weight = 5 identifier = "about" name = "About" pre = "<i class=\"sidebar-button-icon fas fa-lg fa-question\" aria-hidden=\"true\"></i>" url = "/#about" [[menu.main]] weight = 6 identifier = "policy" name = "プライバシーポリシー" pre = "<i class=\"sidebar-button-icon fas fa-info-circle\" aria-hidden=\"true\"></i>" url = "/policy/privacy" [[menu.links]] weight = 0 identifier = "github" name = "GitHub" pre = "<i class=\"sidebar-button-icon fab fa-lg fa-github\" aria-hidden=\"true\"></i>" url = "" [[menu.links]] weight = 0 identifier = "LinkedIn" name = "LinkedIn" pre = "<i class=\"sidebar-button-icon fab fa-lg fa-linkedin\" aria-hidden=\"true\"></i>" url = "" [[menu.links]] weight = 0 identifier = "twitter" name = "twitter" pre = "<i class=\"sidebar-button-icon fab fa-lg fa-twitter\" aria-hidden=\"true\"></i>" url = ""
Netlify上でレンダリングがうまくいかない場合
カスタマイズしたブログの表示が,ローカルでテスト時は問題なくても,Netlifyでホストする際はうまくレンダリングされない場合があります.私の環境では,下記2点を対応することで,解決できました.
config.toml で設定されたbaseURLのパスが原因でアセットを探せない
上記のbaseURLに,/を指定している点です.調べたところ同じような症状の記事があったのでそちらを参考に修正したものです.
ローカルとNetlify上でのHugo version
作業端末のHugo versionとNetlify上のHugo versionが異なる場合もうまくレンダリングされないことがあるようです.特に指定しない場合,Netlifyはデフォルトで,サイトの初期ビルドイメージにはじめからインストールされているHugoのバージョンを使用するようです.
By default we’ll use the Hugo version that is preinstalled in your site’s initial build image. Because the preinstalled version may not match your local version
バージョンを明示的に変更するため,作業のルートディレクトリに,netlify.tomlを作成します.私の環境では,下記の通り設定しました.HUGO_VERSION = "0.101.0"の箇所が,ローカルのHugo versionと一致していれば概ね問題ないはずです.
[build] publish = "public" command = "hugo --theme=tranquilpeak --gc --minify" [context.production.environment] HUGO_VERSION = "0.101.0" HUGO_ENV = "production" HUGO_ENABLEGITINFO = "true"
参考: docs.netlify.com
ファイル追加後,リモートリポジトリにプッシュし,Netlify上のログを確認すると,指定したコマンドが実行され,意図したHugoのバージョンが使用されていることがわかります.

サイトを確認し,指定した形式で表示されていればOKです.

おわりに
Hugoや使用するテーマの設定方法をよく調べる必要がありますが,ソースをGit管理しつつマークダウンで記事を執筆できるのはよいな,という環境構築前の印象の通りでした.
記事にカテゴリやタグ付けすることで,はてなブログでは有料オプションになる,カテゴリごとの記事一覧ページ等の表示ができるのは個人的にはメリットです.
実際に記事を書いてみるとより細かな調節で苦戦する場面はありそうですが,まずは今後も使っていこうと思えるサービスでした.
参考
config.toml については,下記の記事も参考としました. tomtomtom.ga
脆弱性診断の分類
業務にて脆弱性診断について知る必要が出てきたので,基本的な内容を整理しておきたく,記事としました.
脆弱性とは
まずは脆弱性という言葉の定義から.
IPAの資料では,次のような定義をしています.
もう一つ,米国国立標準技術研究所(NIST)のSP800(※)シリーズでは下記のように定義されています.
脅威源によってつけこまれるか衝かれるおそれがある情報システム、システムセキュリティの手順、内部制御、または導入での弱点。*2
※SP800:Special Publications (SP800シリーズ)のこと.NISTの情報技術に関する研究を行うITL(Information Technology Laboratory)において,コンピュータセキュリティに関して研究を行うCSD(Computer Security Division)が発行するコンピュータセキュリティ関係のレポート.セキュリティ分野を幅広く網羅している.
ここで,「脅威源」という言葉が出てきたので,あわせて確認しておきます.SP800シリーズの定義は次の通り.
(i) 脆弱性を故意に悪用することを目指す意図および手法、あるいは (ii) 脆弱性が偶発的に衝かれる状況および手法、のいずれか。 *3
ざっくりいえば脆弱性とは,「情報システムそのものや,その導入によって脅威源から悪用される可能性のある点」といえるでしょうか.
脆弱性診断とは
脆弱性診断についても確認します.脆弱性がシステムやその周辺における弱点なので,その弱点を見つけることを指すことが推測されます.似たような意味で使用される「ペネトレーションテスト」という言葉もあるので,下記の通り定義を引用します.
| 定義 | |
|---|---|
| 脆弱性診断 | ・システムにおけるセキュリティ上の弱点を特定するもの *4 ・脆弱性やセキュリティ機能の不足を「網羅的に洗い出す」ことを目的とし、システムに内在するリスクをすべて洗い出すこと *5 |
| ペネトレーションテスト | ・「脆弱性を悪用する」ことで、明確な意図を持った攻撃者がその目的を達成することが可能であるかどうかを検証すること *6 |
脆弱性診断が対象システムに対し,起こり得る脆弱性を網羅的に確認していくのに対し,ペネトレーションテストにはそういった側面はないことがわかります.ペネトレーションテストでは,対象に侵入可能か検証することがメインで,結果として脆弱性が発見されるという違いがあると理解しておくと良いかもしれません.
ただし,テストベンダーによっては両者を混同している場合もあり,それぞれの文脈で何を指すのかを意識できるようになる必要があると感じました.
脆弱性診断の種類
ここからは,脆弱性診断についてもう少し詳しく見ていきます.脆弱性はシステムのあらゆる場所に潜むので,脆弱性診断自体も,システムのどの部分を対象とするかで分類されます.以下に一般的な分類を表にしています.
| 種類 | 対象 |
|---|---|
| プラットフォーム脆弱性診断 | OS,ミドルウェア,ネットワーク |
| Webアプリケーション脆弱性診断 | Webアプリケーション,アプリケーションミドルウェア |
| モバイルアプリケーション脆弱性診断 | スマートフォンアプリケーション |
種類をわけることができるように,テストベンダーもこの種類ごとにサービスを提供しています.以降は,プラットフォームとWebアプリケーション診断についてさらに見ていきます.
プラットフォーム脆弱性診断
プラットフォーム脆弱性診断では,サーバーやネットワーク機器に対し疑似的な攻撃的な通信を送り,脆弱性を検査します.診断は,通信元によって下記の通り,さらに分類されます.
| 診断 | 内容 |
|---|---|
| 外部(リモート)診断 | 外部からアクセス可能な機器を対象に,悪用可能な脆弱性を明らかにする |
| 内部(オンサイト)診断 | 拠点,LAN内,DMZ等の内部ネットワークから悪用可能な脆弱性を明らかにする |
プラットフォーム脆弱性診断の主要な診断項目は次の通りです.
| 診断項目 | 内容 |
|---|---|
| ポートスキャン | 外部から通信可能なポートを調査し、不要なポートが攻撃に悪用される危険性がないか診断 |
| 各種サーバーに対する脆弱性診断 | OSやミドルウェアのバージョンが外部から取得できないか,脆弱性を含むバージョンでないか診断 |
| 設定の適正チェック | サーバーに最新のセキュリティパッチが適用されているか 等 |
Webアプリケーション脆弱性診断
Webアプリケーションとモバイルアプリケーションは,まとめてアプリケーションとして扱われる場合もあります.こちらでは,WebアプリケーションやWebAPIに疑似的な攻撃リクエストを送ることで,アプリケーションに情報漏洩や改ざんといった脆弱性がないか診断します.
| 診断項目 | 内容 |
|---|---|
| 認証・認可 | ・認証の回避や、ログインIDやパスワードの強度が十分か診断 ・管理者権限への昇格や権限の無い情報へのアクセスができないか診断 |
| セッション管理 | セッションID等の機密情報を含むCookieにおけるsecure属性が欠如していないか診断 |
| 実装の不備 | SQLインジェクション,クロスサイトスクリプティング,ディレクトリトラバーサルへの対策診断 |
クラウド診断
近年は,AWSなどのクラウドサービスを利用したサーバーの構築が一般化しています.クラウドサービスについては,プラットフォーム診断とは別の,クラウドセキュリティ診断やAWS診断といったサービスとして,クラウドベンダーごとの診断サービスを提供するセキュリティベンダーも存在します.
クラウド診断では,下記のような内容が診断されます.
・セキュリティ設定の診断(セキュリティグループ)
・CIS(Center for Internet Security)等のベストプラクティスに基づく製品設定の診断
・各種暗号化の診断(データや通信が適切に暗号化されているか)
・AWSの場合,IAMや各種リソースへのアクセス権など
さいごに
脆弱性診断は,対象領域(プラットフォーム・Webアプリケーション)ごとに分かれること,近年はクラウドサービスに対し,ベストプラクティスに基づく設定状況の診断もサービスとして提供されていることがわかりました.
プラットフォームやWebアプリケーション診断の主要な項目は,おさえておきたいと感じました.
今回の記事執筆にあたり,デジタル庁の
政府情報システムにおける脆弱性診断導入ガイドラインに目を通しましたが,この内容は,記事作成前にまさにまとめた情報として知りたかったことが記載されているので,脆弱性診断について,知る必要が出てきた方にはお勧めします.今回は以上になります.
引用
AWS CLIでVPC フローログを取得する
業務でAWSのVPCフローログを扱う場面があったので,その基礎とCLIでのログ取得までを記事としました.
概要
VPCフローログは,VPCとネットワークインターフェース間を行き来するIPトラフィックに関する情報を取得できる機能です.下記に,公式ドキュメントより概要を引用します.
ログ取得対象
・VPC
・サブネット
・ネットワークインターフェース
VPCやサブネットを対象とする場合は,それぞれのVPC/サブネット内の各ネットワークインターフェースがモニタリングの対象となります.
※ネットワークインターフェース:物理的な環境におけるNIC(Network Interface Card)に相当.インスタンスに付け替えることができる.(一つのEC2インスタンスに,複数のIPアドレスを付与したりできる.)
ログ保管場所
・CloudWatch Logs
・Amazon S3
ログの形式
集約間隔
特定のフローがキャプチャされ、フローログレコードに集約される期間.デフォルトでは,600秒(10分)間隔.集約間隔内に取得されたログは,指定したサービス(CloudWatch Logs またはAmazon S3)に送信されます.送信には,それぞれ5~10分程度要するようです.
デフォルト形式
デフォルトの形式は,ドキュメントより確認できます.送信元/先のポート番号やIPアドレス,action(対象のトラフィックに対する処理 ACCEPT/REJECT)などを確認できます.
使いどころ
VPCフローログ自体は,ログを取得するサービスなので,監視という意味では他のサービスとの連携が必要となります.
・Guard DutyをONにして,異常検知時の詳細をVPCフローログで確認する.
・CloudWatch Alarmと連携し,特定の状況時に管理者に通知する. など
構成
今回は,下記の構成でVPCフローログの取得までを行います.
対象
・EC2インスタンス(ネットワークインターフェース)
ログ保管場所
・CloudWatch Logs

CLIでの環境構築
VPC~EC2インスタンスの構成までは,下記のコードで実施しました.
ここで,EC2作成時にuser-dataを指定し,Apacheを起動させています.
#!/bin/bash yum update -y yum install httpd -y sudo systemctl start httpd.service
また,セキュリティグループを下記の通り設定しています.
| IPバージョン | タイプ | ポート範囲 | ソース |
|---|---|---|---|
| IPv4 | HTTP | 80 | ${MYIP}/32 |
| IPv4 | SSH | 22 | ${MYIP}/32 |
手元の環境から,SSH接続とApacheの画面を確認出来たらフローログ作成に取り掛かります.
VPCフローログの取得
Cloud watch logs ロググループの作成
Cloud watch logs をログの送信先とするので,まずはロググループを作成します.
ログの作成後に,put-retention-policコマンドでログの保持期間を1日に変更しています.(デフォルトでは,保持期間が設定されない)
# Variables PREFIX="blog" # cloudwatch logs log group aws logs create-log-group \ --log-group-name "flow-logs" \ --tags "Key=Name,Value=${PREFIX}-log-group" aws logs put-retention-policy \ --log-group-name "flow-logs" \ --retention-in-days 1
VPCフローログの作成
EC2インスタンス(ネットワークインターフェース)に対するログを取得するので,そのIDを取得しcreate-flow-logsのresource-idsに指定します.また,VPCフローログにCloud watch logs にログを送信するために必要な権限をIAMロールのArnを指定する形で付与します.
ENI_ID=$(aws ec2 describe-instances \ --filters "Name=tag:Name,Values=${PREFIX}-instance" \ --query "Reservations[].Instances[].NetworkInterfaces[].NetworkInterfaceId" \ --output text) && echo ${ENI_ID} aws ec2 create-flow-logs \ --deliver-logs-permission-arn "arn:aws:iam::XXXXX:role/VpcFowlogsRole" \ --log-group-name "flow-logs" \ --resource-ids ${ENI_ID} \ --resource-type "NetworkInterface" \ --max-aggregation-interval 60 \ --traffic-type ALL \ --tag-specifications "ResourceType=vpc-flow-log,Tags=[{Key=Name,Value=${PREFIX}-flow-logs}]"
IAMロールは,下記の内容で作成しておきます.
CloudWatch Logs へのフローログの発行 - Amazon Virtual Private Cloud
その他の基本的なオプションは下記の通りです.
| 引数 | 内容 |
|---|---|
| deliver-logs-permission-arn | VPCフローログに設定するIAMロールのArn |
| log-group-name | CloudWatch Logs logのロググループ名 |
| resource-ids | フローログ作成対象のID |
| resource-type | フローログ作成対象のリソースタイプ(VPC,サブネット,ネットワークインターフェース等) |
| max-aggregation-interval | パケットのフローをキャプチャし、フローログのレコードに集約する時間の最大間隔(60または600秒) |
| traffic-type | ログ取得対象のトラフィックタイプ(ACCEPT,REJECT,ALL) |
ログの確認
フローログを作成後,対象のEC2インスタンスに対し,SSH接続・HTTPリクエストを送り,ログを確認します.
デフォルトのログは下記のような形式です.送信先IP(dstaddr)は,プライベートIPアドレスとなります.MYIP(srcaddr)からEC2のプライベートIPアドレスの22/80番ポート宛に通信が走っていることが確認できます.

https://docs.aws.amazon.com/ja_jp/vpc/latest/userguide/flow-logs.html
ログの形式を変更する
VPCフローログ作成後に,ログ形式の変更はできず,再作成する必要があります.先のVPCフローログを削除し,下記の通りlog-formatを指定することで,今度はログの形式を指定し作成します.
aws ec2 create-flow-logs \ --deliver-logs-permission-arn "arn:aws:iam::XXXXX:role/VpcFowlogsRole" \ --log-group-name "flow-logs" \ --resource-ids ${ENI_ID} \ --resource-type "NetworkInterface" \ --max-aggregation-interval 60 \ --traffic-type ALL \ --log-format '${version} ${srcaddr} ${dstaddr} ${srcport} ${dstport} ${protocol} ${type} ${pkt-srcaddr} ${pkt-dstaddr} ${flow-direction} ${traffic-path} ${action}' \ --tag-specifications "ResourceType=vpc-flow-log,Tags=[{Key=Name,Value=${PREFIX}-flow-logs}]"
新しくキャプチャされたログは下記のようになります.必要な情報のみを選択できるので,ログ保管のコスト削減も期待できそうです.

アクセス内容の確認
下記のブログにも記載がある内容ですが,フローログを確認すると多数のIPアドレスから様々なポート宛てにリクエストがあることがわかります.CloudWatch Logs Insightsで,今回作成したインスタンスに対し,セキュリティグループで拒否された通信の宛先ポート番号の一部を図にしています.利用環境に応じては,セキュリティグループをしっかりと設定しておくことは必須に感じます.
filter @message like /REJECT/ |parse @message '* * * * * * * * * * * *' as version,srcaddr,dstaddr,srcport,dstport,protocol,type,pkt_srcaddr,pkt_dstaddr,flow_direction,traffic_path,action | stats count(*) as Ports by dstport | sort Ports desc | limit 15

まとめ
今回は,CLIでフローログを取得するところまでをまとめましたが,実運用ではこのログを監視し,異常があればアラートをあげる等あると思います.次回以降,簡単なイベント通知なども検証してみようと思います.今回は以上になります.
AWS CLIでAssumeRoleとPassRoleする
AWS IAMにおける,AssumeRole・PassRoleの利用についての備忘録的な記事になります.
AWS IAM
IAMは,各種リソースへのアクセスを安全にコントロールするために使用されるサービスです.
AssumeRole
AssumeRole は,AWSのリソースが,IAMロールを引き受けることを表します.
PassRole
PassRole は、 AWSのリソースに IAMロールを渡す(パスする)ことを表します.
今回やりたいこと
本記事では,下図の内容をCLIで実施しながら,AssumeRole・PassRoleの挙動を確認します.

①:開発用のIAMユーザー(dev-user)を作成し検証
②:dev-userがEC2を作成できるような一時権限を取得
③:dev-userでEC2を作成し,EC2にS3読み取りの権限を付与する
②では,dev-userがIAM ロールに設定された権限(EC2作成権限)を引き受けます.
③では,dev-userがEC2にIAMロールに設定された権限(S3読み取り権限)を付与します.(同時にEC2は,S3読み取り権限を引き受けることになります.)
AssumeRole
作業用のIAMユーザーを作成
まずは管理者権限を持つユーザーにて,今回の作業用IAMユーザーを作成します.
ユーザー名はdev-userとします.現時点では何の権限もありません.
#ユーザーの作成 aws iam create-user \ --user-name dev-user \ --path "/blog/dev/" #Arnの確認 aws iam list-users \ --path-prefix "/blog/dev/" \ --query 'Users[].Arn' \ --output text
IAMロールを作成
dev-userが引き受けることになる,IAMロール(EC2作成権限)を作成します.
TRUST_FILE='./trust-ec2-create-role.json' cat << EOF > ${TRUST_FILE} { "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": "sts:AssumeRole", "Principal": { "AWS": "arn:aws:iam::XXXXX:user/blog/dev/dev-user" } } ] } EOF #Roleの作成 aws iam create-role \ --role-name ec2-create-role \ --assume-role-policy-document file://trust-ec2-create-role.json \ --path "/blog/dev/"
信頼関係のActionに,AssumeRoleが出てきます.
PrincipalにIAMユーザー(dev-user)のArnを指定することで,dev-userがこのIAMロールを引き受けることができるようになります.
※ユーザー名で指定する方法の場合、上記のように信頼関係の設定のみで,ユーザーにもIAMロールを引き受ける権限(sts:AssumeRole)が許可されます.アカウントの場合,ユーザーのポリシーの設定も必要となります.
上記で作成したIAMロールにアタッチするポリシーを作成します.EC2を作成できればよいので,ec2:RunInstancesを許可します.
また,後ほどEC2にロールを付与する(PassRole)ために,事前にec2:AssociateIamInstanceProfile ec2:ReplaceIamInstanceProfileAssociationも許可しておきます.
POLICY_FILE='./policy-ec2-create.json' cat << EOF > ${POLICY_FILE} { "Version": "2012-10-17", "Statement": [ { "Sid": "", "Effect": "Allow", "Action": [ "ec2:RunInstances", "ec2:AssociateIamInstanceProfile", "ec2:ReplaceIamInstanceProfileAssociation" ], "Resource": "*" } ] } EOF #policyを作成 aws iam create-policy \ --policy-name policy-ec2-create \ --policy-document file://policy-ec2-create.json
下記のコマンドで,ロールにポリシーをアタッチします.
#ポリシーのArnを取得 POLICY_ARN=$(aws iam list-policies --query 'Policies[?starts_with(PolicyName,`policy-ec2`)].Arn' \ --output text) && echo ${POLICY_ARN} #ロールにポリシーをアタッチ aws iam attach-role-policy \ --role-name ec2-create-role \ --policy-arn ${POLICY_ARN}
これで,dev-userはEC2を作成する権限を引き受ける準備ができました. 以降,dev-userで作業するために,dev-userのアクセスキーを発行しておきます.
aws iam create-access-key --user-name dev-user
AssumeRoleの実施
dev-userに切り替え,何もしていない状態で,EC2インスタンスを立ち上げる下記のコマンドを実行してみます.
aws ec2 run-instances \ --image-id ami-0fe23c115c3ba9bac \ --count 1 \ --instance-type t2.micro \ --associate-public-ip-address
現時点では,権限がないため,エラーとなります.
An error occurred (UnauthorizedOperation) when calling the RunInstances operation: You are not authorized to perform this operation.
EC2作成用のロールを引き受けます.(AssumeRoleします)
aws stsコマンドを使用し,対象のIAMロールのArnにEC2作成用のロールArnを指定します.
aws sts assume-role \ --role-arn "arn:aws:iam::XXXXX:role/blog/dev/ec2-create-role" \ --role-session-name temp-session \ --duration-second 900
実行すると,下記のように一時的なクレデンシャルを取得できます.
{
"Credentials": {
"AccessKeyId": "XXX",
"SecretAccessKey": "XXX",
"SessionToken": "XXX",
"Expiration": "2022-07-02T08:41:21+00:00"
},
"AssumedRoleUser": {
"AssumedRoleId": "XXXXXXXXXX:temp-session",
"Arn": "arn:aws:sts::XXXXX:assumed-role/ec2-create-role/temp-session"
}
}
環境変数AWS_ACCESS_KEY,AWS_SECRET_ACCESS_KEY,AWS_SESSION_TOKENを上記で取得したものに置き換えることで一時的な認証情報で作業します.
変更が適用されているかどうかは,下記のコマンドで作業中のプロファイルすることで判断できます.
aws sts get-caller-identity
{
"UserId": "XXXXXXXXXXXXXXX",
"Account": "XXXXX",
"Arn": "arn:aws:iam::XXXXX:user/dev-user"
}
この状態で,上記のaws ec2 run-instancesを実行するとEC2インスタンスを起動することができます.
PassRole
作成したEC2インスタンスには,他のリソースを操作する権限はないので,EC2からaws s3 lsとしても権限不足によるエラーとなります.
EC2からS3バケットを読み取ることができるように,dev-userからEC2にIAMロールを付与します.
dev-userで上記のIAMロールをAssumeRoleした状態で,下記のコマンドを実行します.
aws ec2 associate-iam-instance-profile \ --instance-id i-03f95fdd292ae52b4 \ --iam-instance-profile Name=s3readInstanceProfile
コマンドでは,作成済みの(※作成手順は記事最後に記載)インスタンスプロファイルを,先程作成したEC2に紐づけていますが,このコマンドの実行結果はエラーになります.dev-userには,EC2インスタンスにIAMロールを渡す(PassRoleする)権限がないためです.
※この場合,厳密にはインスタンスプロファイルに紐づいたIAMロールを渡そうとしています.
公式ドキュメントを確認しておきます.
下記の通り,EC2にIAMロールを付与するには,PassRoleが必要なことがわかります.
dev-userが引き受けた,EC2作成用のIAMロールに,ec2:RunInstances以外の許可を与えたのはこのためです.
IAM ロールを持つインスタンスの起動、および既存インスタンスへの IAM ロールのアタッチと置換を許可するには、以下の API アクション を実行するためのアクセス許可を付与します。
- iam:PassRole
- ec2:AssociateIamInstanceProfile
- ec2:ReplaceIamInstanceProfileAssociation
PassRole可能なIAMロールを作成
この作業は管理者権限を持つIAMユーザーで実施しています.
EC2作成用のIAMロールのポリシーを変更し,PassRole付きのポリシーとします.ActionPassRoleのResourceに,S3への読み取り権を持つIAMロール(※事前作成済み.作成方法は記事先後に記載.)を指定することで,このポリシーを付与されたリソースは,他のリソースにS3アクセスの権限をPassできるようになります.
TRUST_POLICY_FILE='./policy-ec2-create.json' cat << EOF > ${TRUST_POLICY_FILE} { "Version": "2012-10-17", "Statement": [ { "Sid": "", "Effect": "Allow", "Action": [ "ec2:RunInstances", "ec2:AssociateIamInstanceProfile", "ec2:ReplaceIamInstanceProfileAssociation", ], "Resource": "*" }, { "Effect": "Allow", "Action": "iam:PassRole", "Resource": "arn:aws:iam::XXXXX:role/s3read" } ] } EOF #先に作成したポリシーを作り直すために,一旦IAMロールからdetach POLICY_ARN=$(aws iam list-policies --query 'Policies[?starts_with(PolicyName,`policy-ec2`)].Arn' \ --output text) && echo ${POLICY_ARN} aws iam detach-role-policy \ --role-name ec2-create-role \ --policy-arn ${POLICY_ARN} #PassRoleの権限がないポリシーを削除 aws iam delete-policy --policy-arn ${POLICY_ARN} #PassRoleの権限があるポリシーを作成 aws iam create-policy \ --policy-name policy-ec2-create \ --policy-document file://policy-ec2-create.json #新しく作成したポリシーのArnを取得 POLICY_ARN=$(aws iam list-policies --query 'Policies[?starts_with(PolicyName,`policy-ec2`)].Arn' \ --output text) && echo ${POLICY_ARN} #ec2 create roleにPassRole可能なポリシーをアタッチ aws iam attach-role-policy \ --role-name ec2-create-role \ --policy-arn ${POLICY_ARN}
PassRoleを実施
ここから,dev-userで作業します.
dev-userにて,PassRoleの権限を付与したEC2作成用のIAMロールを引き受けます.
#dev-userで実施 aws sts assume-role \ --role-arn "arn:aws:iam::XXXXX:role/blog/dev/ec2-create-role" \ --role-session-name temp-session \ --duration-second 900
作成済みのEC2に,先程のIAMロールでは,エラーとなった下記のコマンドを実行し,S3読み取り権限を持つインスタンスプロファイルを紐づけます.
aws ec2 associate-iam-instance-profile \ --instance-id i-03f95fdd292ae52b4 \ --iam-instance-profile Name=s3readInstanceProfile
{
"IamInstanceProfileAssociation": {
"AssociationId": "iip-assoc-01c1886db23b64937",
"InstanceId": "i-0d8012d6a3f4abf80",
"IamInstanceProfile": {
"Arn": "arn:aws:iam::XXXXX:instance-profile/s3readInstanceProfile",
"Id": "XXXXXXXXXXX"
},
"State": "associating"
}
}
PassRoleの権限を付与したことで,問題無く実行できるようになります.
EC2からもS3の読み取りができるようになります.
まとめ
個人的に,AssumeRoleと特にPassRoleのイメージがあまりわかなかったのですが,CLIを通して細かく設定していくことで,基本的でありながらセキュリティの観点では,理解必須の機能であることを再認識できました.今回は以上になります.
(※)S3読み取り権限を持つインスタンスプロファイルの作成
EC2に付与するS3読み取り可能なIAMロールの作成手順です.
※この作業は管理者権限を持つユーザーで実行しています.
TRUST_POLICY_FILE='./ec2-role-trust-policy.json' cat << EOF > ${TRUST_POLICY_FILE} { "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "ec2.amazonaws.com"}, "Action": "sts:AssumeRole" } ] } EOF #IAMロールの作成 aws iam create-role \ --role-name s3read \ --assume-role-policy-document file://ec2-role-trust-policy.json #IAMポリシーのArnを取得 POLICY_ARN=$(aws iam list-policies --query 'Policies[?starts_with(PolicyName,`AmazonS3ReadOnlyAccess`)].Arn' \ --output text) && echo ${POLICY_ARN} #IAMロールにポリシーをアタッチ aws iam attach-role-policy \ --role-name s3read \ --policy-arn ${POLICY_ARN}
インスタンスプロファイルにIAMロールを紐づけます.
#インスタンスプロファイルを作成 aws iam create-instance-profile \ --instance-profile-name s3readInstanceProfile #インスタンスプロファイルとIAMロールを紐づけ aws iam add-role-to-instance-profile \ --role-name s3read \ --instance-profile-name s3readInstanceProfile
IICSでS3から複数ファイル読み込み
IICS(Informatica Intelligent Cloud Services)のデータ統合機能で、S3から複数ファイルを読み込む必要があったので、その際に調べた方法をまとめたものです。また後でわかったことですが、有償版であれば「一括取り込み」機能でもっと簡単に実装できるようです。
IICSとは
IICS(Informatica Intelligent Cloud Services)は、Informatica社が提供するクラウド型のデータ統合ソリューションです。SaaS型のETLツールといってもよいかもしれません。
一般的なETLとしての、各種データソースからのデータ抽出、統合処理、ロードまでをGUIで実装できます。
前提条件
IICSは、公式サイトより30日間の無償トライアルを利用できます。一部機能は制限されますが、基本的なデータ統合処理を試すことは可能です。
IICSでは、ランタイム環境として提供される「Secure Agent」をサーバーにインストールすることで、データを外部に出すことなく処理を実行できます。
今回は下記の環境を用意しました。EC2上にSecure Agentをインストールしています。

EC2へのSecure Agentのインストールは、クラスメソッド様の記事が参考になります。
IICS Secure AgentをWindows環境にインストールしてみる | DevelopersIO
処理概要
IICSで下記の手順を実施します。
1.データソースとの接続を作成
2.マニフェストファイルを作成
3.ジョブの作成
ソースにS3、ターゲットにはRedshiftを使用します。
また、事前に下記のようなデータファイルを作成し、S3の所定の階層にアップロードしておきます。
S3の階層は<バケット名>/informatica/sampleとしています。
・サンプルデータ(data-01.csv)
| id | val | file |
|---|---|---|
| 1 | 41 | file1 |
| 2 | 36 | file1 |
| 3 | 10 | file1 |

1ファイル10行のデータを、10ファイルに分割し配置(合計100行のデータ)。列「file」にはファイル番号を入力。
データソースとの接続を作成
ここから、IICSでの作業に入ります。まずはデータソースに使うS3とRedshiftの接続を作成します。
IICSの管理者画面より「新しい接続」を作成します。
- S3
下記の通り設定しました。「Use EC2 Role to Assume Role」にチェックを入れることで、EC2に付与したS3への読み取り権限をIICSでも使用しています。

- Redshift
こちらは直接接続情報を入力しています。JDBCURLを使用することに注意してください。

マニフェストファイルの作成
S3から複数ファイルを読み込むには、マニフェストファイルを作成します。詳細はマニュアルに記載があり、雛形としても使用できます。(PowerCenterのマニュアルですが同様の設定で問題ありませんでした。)
今回は、すべてのファイルが同じ階層にあるので、下記のように設定しました。マニュフェストファイルを作成したら、同じS3バケットにアップロードしておきます。
{
"fileLocations": [{
"WildcardURIs": [
"informatica/sample/data_*.csv"
]
}, {
"URIPrefixes": [
"<バケット名>/"
]
}],
"settings": {
"stopOnFail": "true"
}
}
ジョブの作成
新規のマッピングタスクを起動し、ジョブを作成します。今回のジョブは下図の通りです。データを左から右に流すシンプルなつくりです。

- ソースの設定
ソースのプロパティは下記のように設定しました。

オブジェクトの設定では、先程作成したマニュフェストファイルを指定します。

形式には「フラットファイル」を指定します。オプションで区切り文字やヘッダーの有無を指定します。

また、今回は、スキーマを別ファイルで作成しインポートしています。
IICSで各種データを読み込む際は、データのスキーマを定義する必要があります。ソースがデータベースであればスキーマ情報を取得できますが、ファイルの場合、全項目が「String」型として扱われます。
列数が少ない際は、「フィールド」設定からGUIで編集しても良いですが、列が多い場合はミスの原因となります。
json形式で定義したスキーマ情報を適用することができるので、この場で指定しています。
スキーマは下記のように定義しました。
{"Columns": [ {"Name":"id","Type":"number","Precision":"316","Scale":"0"}, {"Name":"val","Type":"number","Precision":"316","Scale":"0"}, {"Name":"file","Type":"string","Precision":"316","Scale":"0"} ] }
ファイルを適用後、スキーマ情報が更新されていることを確認します。

- ターゲットの設定
ターゲットの設定は下記の通りです。publicスキーマに、「informatica_out」という新規テーブルを作成することとしました。

IICSでターゲットをRedshiftとする際は、ターゲットの詳細設定の「S3 Bucket Name」を指定しなければいけないので、今回使用するバケット名を記入しておきます。
また「Copy Options」に下記を記述し、インサート時にはコピーコマンドが呼び出されるようにしておきます。(事前にRedshiftへS3に対する権限は付与しておきます。)
「Copy Options」欄にコピーコマンドのオプションを記述する際のオプションの区切りにはセミコロンを使用することに注意してください。マニュアルでは、ロールARNの区切り文字にもセミコロンが使用されていますが、この部分はコロンでないとエラーとなります。
DELIMITER=,;AWS_IAM_ROLE=<iam role arn>

また、Redshiftのコピーコマンドの実行時は、Secure Agentに下記の設定を済ませておくことを推奨します。

テーブルの確認
上述の設定後、ジョブを実行します。問題無く実行出来たら、Redshift側でテーブルを確認します。



まとめ
有償版の「一括取り込み」機能であればもっと簡単に実装できるようですが、データ統合機能のみでも複数ファイル読み込みが実行できることを確認できました。この場合、Informaticaの機能というよりは、Redshiftの機能を呼び出すことになるのですが、複雑な処理を実装しようとすると、ツール以外のリソースの機能もある程度抑えておく必要がありそうです。
今回は以上になります。
TalendでELT処理を実施する
ETLツールとして有名なTalendですが、ELT処理を実施するためのコンポーネントが用意されています。データベース側の挙動もあわせて使用感を確認してみました。
前提条件
「Talend Open Studio for Data Integration」の「Version 8.0.1」で検証を実施しました。
ELT処理の対象となるデータベースには、Snowflakeを使用しました。 (Snowflake環境は構築済みとします。)
Snowflake側の準備
今回の検証用に、Snowflake側でデータベース・スキーマを定義します。
create database test; create schema talend;
作成したスキーマに、統合処理に使うテーブルを定義します。
CREATE OR REPLACE TABLE STUDENT ( ID VARCHAR(316), NAME VARCHAR(316) ); INSERT INTO STUDENT (ID,NAME) VALUES ('C01','Shohei'), ('C02','Mike'), ('C03','Anthony'), ('C04','Jack'), ('C05','Max'), ('C06','Matt') ;
CREATE OR REPLACE TABLE TEST ( ID VARCHAR(316), SUBJECT VARCHAR(316), SCORE NUMBER(38,0) ); INSERT INTO TEST (ID,SUBJECT,SCORE) VALUES ('01','Math',60), ('01','English',70), ('02','Math',50), ('02','English',80), ('03','Math',70), ('03','English',80), ('04','Math',50), ('04','English',40), ('05','Math',80), ('05','English',30), ('06','Math',70), ('06','English',70)
下記の処理をTalendのELTコンポーネントで実装します。
SQLでいうところの、Join・Group By・Having句が入ってくるような処理を想定します。
1.「Student」テーブルと、「Test」をIDで結合(「Test」テーブルのID列の先頭に文字列'C'を付与し結合)
2.生徒ごとに全テストの合計点数を算出し、合計が130点以上の生徒を抽出
Talend側の処理
作成したジョブ
上記の処理をELTコンポーネントで、下図のように実装しました。

Snowflakeとの接続
まずはリポジトリからSnowflakeの対象とするデータベースへの接続を作成します。

Snowflakeとの接続に必要な情報は下記の通りです。
Account:SnowflakeのコンソールのURLから取得
User ID:Snowflakeのコンソールへログインする際のユーザー名
Password:Snowflakeのコンソールへログインする際のパスワード
Warehouse:使用するウェアハウス(コンピュートエンジン)の名称
Schema:使用するスキーマの名称
Database:使用するデータベースの名称
Snowflakeのコンソールでは、URLのsnowflakecomputing.comの前に、アカウント情報・Snowflakeの構築に使用しているクラウドサービス情報が記載されています。Account欄にはこの情報を記載します。

接続確認が取れたら、ジョブの作成に入ります。
ジョブ全体図のPrejob・Postjobの通り、データベースへの接続には各種の接続用コンポーネントを使用します。
tELTInputコンポーネント
ここから、ELT処理の実装に入ります。ELT処理を実施する際は、通常のInputコンポーネントではなく、tELTInputコンポーネントを使用します。今回は2つのテーブルを使用するので、2つ配置しています。 コンポーネントの設定は下図の通りです。

スキーマ名をコンテキスト変数で設定し、テーブル名はそのまま入力しています。使用するテーブルのスキーマを定義し、MappingにMapping Snowflakeを指定します。
tELTMap
統合処理には、tELTMapコンポーネントを使用します。設定は下記の通りです。

①:結合条件の指定
今回の場合、TestテーブルのID列先頭に文字列を付与する必要があります。TestテーブルのID列をStudentテーブルのID列にドラッグアンドドロップします。

式ビルダを開き、下記の通り文字列の結合処理を定義します。

ここでは、concat()を使用し、TestテーブルのID列先頭に文字Cを付与しています。Talend Studioには無くても、Snowflakeで定義されていれば関数を使用することができます。
最後には、StudentテーブルのID列・NAME列も表示したいので、新しい出力を下記の通り作成しておきます。

②、③:集計処理
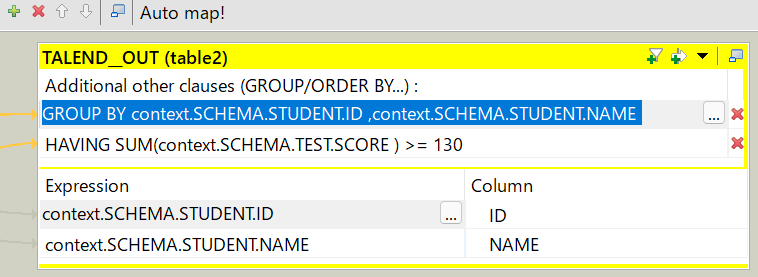
生徒ごとの点数合計を作成します。出力の設定で「Add an other (GROUP...) clause」を押下し、式ビルダを表示します。


式ビルダには、下記のように入力します。
GROUP BY context.SCHEMA.STUDENT.ID ,context.SCHEMA.STUDENT.NAME
さらに今回は、集計後の値で絞り込みを行いたい(having句を記述したい)ので、再度、出力の設定から「Add an other (GROUP...) clause」を押下し、別の式ビルダを表示し下記の通り入力します。
HAVING SUM(context.SCHEMA.TEST.SCORE ) >= 130
入力後は下記のようになっているはずです。
④,⑤:集計列の追加
集計した生徒の合計点数は、テーブルでも表示したいので、画面右下の出力スキーマの編集箇所より列を追加し、列名・データ型を指定します。

スキーマを追加すると、出力欄にも列が追加されるので、式ビルダより下記のように入力します。
SUM(context.SCHEMA.TEST.SCORE )

これで統合処理の設定は完了です。tELTMapコンポーネントの設定画面左下の「Generated SQL」タブを開くと設定した内容をもとに、SQL文が生成されています。この画面は随時更新されるので、ここを確認しながら設定を進めていくことになるかと思います。

"SELECT " +context.SCHEMA+ ".STUDENT.ID, " +context.SCHEMA+ ".STUDENT.NAME, SUM(" +context.SCHEMA+ ".TEST.SCORE ) FROM " +context.SCHEMA+ ".STUDENT , " +context.SCHEMA+ ".TEST WHERE " +context.SCHEMA+ ".STUDENT.ID = concat('C', " +context.SCHEMA+ ".TEST.ID) GROUP BY " +context.SCHEMA+ ".STUDENT.ID ," +context.SCHEMA+ ".STUDENT.NAME HAVING SUM(" +context.SCHEMA+ ".TEST.SCORE ) >= 130 "
tELTOutputコンポーネント
作成した統合処理の内容を、データベースで実行する方法を指定します。
今回は、下記のように新規テーブルを作成することとしました。スキーマ同期を忘れないように注意してください。

Snowflakeのログを確認
エラー無くジョブを実行出来たら、Snowflake側でログを確認してみます。


生成した統合処理をもとに、新規テーブルが作成されていることが確認できます。データも確認します。
select * from TALEND_OUT ;

合計が130以上の生徒のデータに絞り込まれていることを確認できます。
まとめ
ELT処理となると、多少SQLの知識が求められますが、GUIでスムーズに構築ができる点はTalendの特徴に感じました。また、Talendの機能は制限されてしまいますが、その代わりデータベースの関数をそのまま使用できるので、SQLに慣れている人からすると、この方がジョブも構築しやすいのではないでしょうか。
今回は機能を使ってみたのみで、ELTのメリットである、データベース側のリソースを使用することによるETLとの処理性能のような観点は見れていないですが、この点も確認してみると面白いかもしれません。
今回は以上になります。