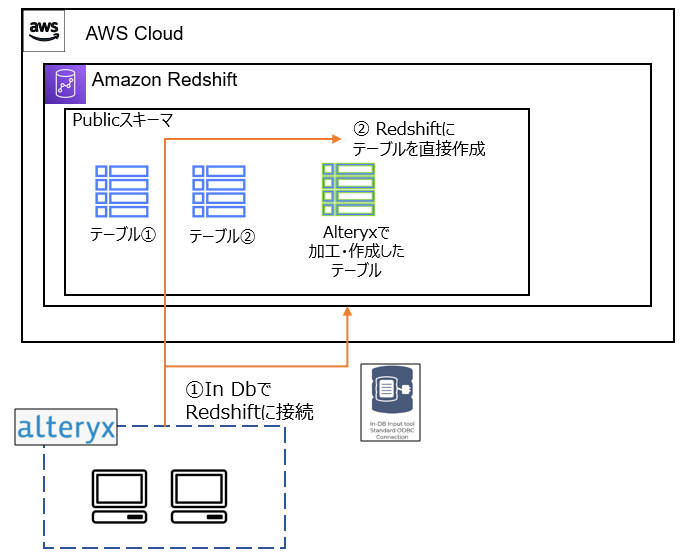
本記事は,「Alteryx Write Data In-DB Toolを用いた新規テーブル作成①(Redshift環境構築~Alteryxからの接続)」の続きにあたります.Write Data In-DB ToolをRedshiftで使用する際に,AWS コンソール側での見え方やこのツールの挙動自体を記した記事は中々見当たらなかったため,前回構築した環境にて下記の内容を確認していきます.
1.1. オプション
ツールで使用可能なオプションは下記の5つです.
1.2. オプションごとに必要な権限
上述のオプションを実行する際は,Alteryxで接続したユーザーが操作対象のテーブルに対して,適切な権限を持つ必要があります.それぞれ下記の権限が必要となります.
オプションと実行に必要な権限
以降の内容は,この検証となります.
2. 管理者ユーザーでのツール使用
権限周りの前に,ツールの挙動・AWS コンソール上からの見え方を確認しておきます.まずは,管理者権限で以降の処理を試します.
2.1. 新規テーブルの作成
管理者権限でAlteyxからRedshiftに接続し,デフォルトで用意されている「category」テーブルに接続します.テーブルの内容は下記の通りとなっています.
categoryテーブル
このテーブルに対し,下記の処理を実行します.③のWrite Data In-DB Toolにて,出力モードを「新しいテーブルを作成する」とし,集約後のデータを書き出しています.
ワークフロー:新規テーブルの作成
Write Data In-DB Toolの設定
フロー実行後,Redshift上でテーブルを確認します.クエリエディタで下記の処理を実行します.
SELECT DISTINCT tablename
FROM pg_table_def
WHERE schemaname = 'public' AND tablename NOT LIKE'%_pkey'
ORDER BY tablename;
クエリ結果画面にて,Alteryxで作成した「aws _user_test1」テーブルを確認できました.
テーブルの確認
データの確認
今回は特に設定などしていませんが,デフォルトで作成される「public」スキーマ 上にテーブルが作成されるようです.
2.2. テーブルの更新
先程作成した「aws _user_test1」テーブルの内容を更新します.「catgroup」が「Sports」の行を削除するように変更してみます.ワークフローを下記の通り,Write Data In-DB Toolの出力モードを「データを削除して付加する」に変更し,データを書き出します.
ワークフロー:テーブルの更新
実行後,Redshift上でテーブルを確認すると下記の通り,「catgroup」が「Sports」を除くデータにテーブルが変更されていました.
データの確認
Alteryx上のツール実行時メッセージを確認すると,下記の表示となっており,公式ドキュメントの記載通り「元あったデータをすべて削除→ツールのインプットとなるデータを追加する」という処理が実行されていることが見てとれました.
Alteryx:ツール実行時メッセージ
なお,このオプション実行時は,下図赤枠内のさらに詳細な設定を選択可能となります. いずれもデータ付加時に,ツールのインプットデータの列構成が更新対象テーブルと異なる場合に,どのような処理とするかを制御可能です.こちらは公式ドキュメントに詳細の記載があるので,そちらをご参照ください.
詳細設定
2.3. テーブルの上書き
次に「テーブルを上書きする(ドロップ)」オプションを実行して見ます.「category」を接続元とし,下記のフローを実行します.ここでは,上書き対象のテーブル名として先程作成した「aws _user_test1」テーブルとしています.こちらは問題無く実行されます.
ワークフロー:テーブルの上書き
Alteryx:ツール実行時メッセージ
処理としては,「元あったテーブルを削除」する処理が実行されているので,作成済みのテーブルと異なるテーブル構造で同じ名称を指定しても,新たなテーブルが作成されることが見てとれました.作成したテーブルの構造自体を変更したい場合は,このツールが使えそうですが,既存テーブルをドロップすることになるため,誤って既存の他テーブルを指定しないように注意する必要がありそうです.
2.3. 一時テーブルの作成
データ加工には必要だが,新規でテーブルを作成するほどの必要が無い場合はこのオプションが便利です.「新規テーブルの作成」と同様のフローでツールオプションを「一時テーブルを作成する」に変更し,実行するとツールの結果ウィンドウに下記のようなメッセージが表示されます.
ワークフロー:「一時テーブルを作成する」オプションの実行
ツール側で機械的 に付与された名称でテーブルが作成されていることがわかります.一時テーブルですので,ツール実行後にクエリエディタで確認しても,このテーブルは確認できません.
3. 一般ユーザーでのツール使用
3.1 新規ユーザーの作成
先程はすべての権限をもつ管理者ユーザーでの実行だったので,各種オプション実行に必要な権限を確認するために,一般ユーザーを作成します.Redshift上のクエリエディタに管理者ユーザーで接続し,下記の通りユーザーを作成します.
CREATE USER test_user PASSWORD 'Testuser1' ;
一般ユーザーの「public」スキーマ 上の各テーブルに対する,デフォルトの権限は以下の通りです.管理者ユーザーである「aws _user」はすべての権限を持ちますが,先程作成した「test_user」は,デフォルトで下記の権限のうちでは,「public」スキーマ に対するusage,create権限を持ちます.
ユーザーごとのテーブルに対する権限
3.2 一般ユーザーでの接続
SELECT権限 ワークフロー:一般ユーザーのデフォルト権限での実行結果
CREATE USER test_user PASSWORD 'Testuser1' ;
test_userへのcategoryテーブルに対するSELECT権限の付与
SELECT権限を付与した「category」テーブルと,未付与の「aws _user_test1」テーブルへの参照を実施します.結果は下図の通り,SELECT権限を付与した「category」テーブルは閲覧でき,SELECT権限の無い「aws _user_test1」テーブルは参照できないことが確認できました.
ワークフロー:categoryテーブルへのSELECT権限付与後の実行結果
CREATE権限 スキーマ へのCREATE権限が付与されているので,問題無く実行されます.
ワークフロー:新規テーブルの作成(一般ユーザー)
一般ユーザーのデフォルト権限で作成したテーブル
一般ユーザーで作成したテーブルのユーザーごと各種権限
INSERT権限 ・DELETE権限 ワークフロー:「既存のものを付加する」オプションの実行
ツール実行後,AWS のクエリエディタで確認すると追加されていることが確認できます.
SELECT *
FROM test_user_test
WHERE catname = 'TEST' ;
追加されたデータ
続いて同じテーブルを対象に上記のフローで,WriteData In DBツールのオプションを「データを削除して付加する」に変更し実行し,下記のデータを追加してみます.
こちらも問題無く実行され,データも指定したデータのみになっていることがマネジメントコンソール上からも確認できました.
オプション「データを削除して付加する」実行後
それでは,権限を削除して確認を行います.
REVOKE DELETE ON test_user_test FROM test_user ;
その後,再度「データを削除して付加する」オプションを実行すると下記の通りエラーとなります.
ワークフロー:「データを削除して付加する」オプションの実行
この状態では,オプションを「既存のものを付加する」に変更しても問題無く実行されます.
REVOKE INSERT ON test_user_test FROM test_user ;
DROP 権限テストテーブルへの権限
ワークフロー:「テーブルを上書きする(ドロップ)」オプションの実行
テーブルを上書きする(ドロップ)後の権限
ALTER TABLE test_user_test OWNER TO test_user;
所有者の権限移譲後,管理者ユーザーで下記の通り,一般ユーザーのドロップ権限のみを付与し,ツールを実行すると,ワークフローもエラー無く実行されることが確認できました.
GRANT DROP ON test_user_test TO test_user ;
4. public以外のスキーマ の使用
次に,public以外のスキーマ に属するテーブルを使用した場合の一部処理を確認します.
下記の通り,スキーマ を作成し,一般ユーザーである「test_user」に権限を付与します.
CREATE SCHEMA test_schema AUTHORIZATION test_user ;
作成した「test_schema」にテスト用テーブルを作成します.
CREATE TABLE test_schema.test_tbl (id int) ;
INSERT INTO test_schema.test_tbl VALUES
(1),
(2),
(3),
(4) ;
このスキーマ とテーブルに対する権限は下記の通りです.
新規スキーマ への権限
4.2 publicスキーマ 以外に属するテーブル接続とテーブル作成
Alteryxから管理者ユーザーで,「test_schema」上の「test_tbl」に接続し下記の通りフローを実行します.
ワークフロー:テストスキーマ への接続と新規テーブル作成
フロー実行後,AWS のクエリエディタでテーブルの定義を確認します.
SELECT * FROM pg_table_def WHERE tablename = 'aws_user_test2' ;
テーブル定義
publicスキーマ 以外のデータのみを使用したとしても,Alteryxからテーブルを作成する場合は,publicスキーマ が指定されテーブルが作成されるようです.
5. データ型
最後に,Alteryx側で新規に列を追加した場合,Redshift上ではどのようなデータ型に変換されるのかを見ていきます.スキーマ への接続と新規テーブル作成」にて使用したワークフローのフォーミュラツールのオプションを下記の通りとします.
フォーミュラツールの設定
この実行結果より作成された5列のデータ型をRedshift上で確認すると下記の通りとなっていました.
Type列がRedshift上でのデータ型(columnはAlteryxのデータ型名)
Alteryxのデータ型からそれぞれ自動的に変換してくれるようです.ただし,可変長文字列や実数のスケールは,ツールインプットを格納可能な最大値を設定してくれるようです.
id
v_wstring
int64
double
bool
5
ABCDEFGHIJ
1
1.0
TRUE
フローは下記の通りです.
ワークフロー:「既存のものを付加する」オプションの実行
すると下記のようなエラーが出力されます.
Error: データ書込In-DB (20): PreSQLを実行: "INSERT INTO "datatype"WITH "Tool18_42e7" AS (SELECT * FROM "AYX2201155ffd41cf519f7c808d2a3b4f2e5f3b50") SELECT "id", "v_wstr..." : [Amazon][Amazon Redshift] (30) Error occurred while trying to execute a query: [SQLState XX000] ERROR: Value too long for character type
DETAIL:
-----------------------------------------------
error: Value too long for character type
code: 8001
context: Value too long for type character varying(9)
query: 1620
location: string.cpp:192
process: query0_127_1620 [pid=10621]
-----------------------------------------------
新規テーブル作成時に,そのデータから最適なスケールを決めてくれるので,後々その容量を上回るデータを追加する場合は,データ構造の変更が必要なようです.